iOS 天问 第3讲

一、 如何快速比较两个数组的相同元素
- 排序 对于
iOS而言, 一般使用系统的sort方法, 然后 元素对象实现一个compare方法 - 比较
- 已排序的数组, 比如升序 , 从数组长度比较大的那个
ArrayLong作为基准, 依次与另一个数组ArrayShort比较, 如果小于则ArrayShort索引加一; 如果等于则 记录此时两者的位置; 如果大于, 则ArrayLong索引加一
- 已排序的数组, 比如升序 , 从数组长度比较大的那个
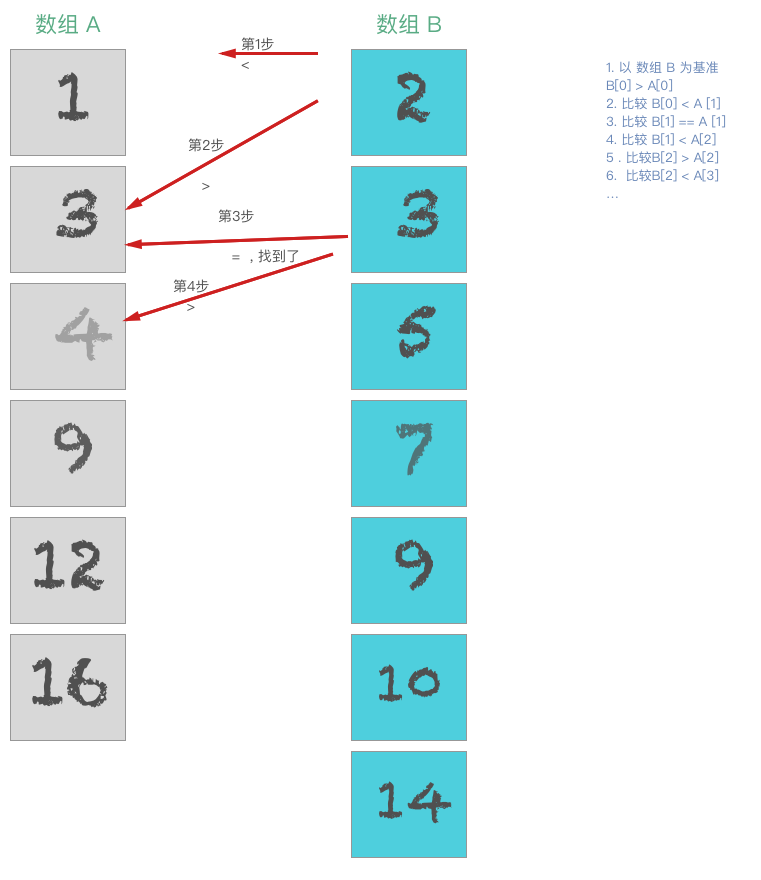
注意 上面的方法仅仅适用于 比较的数组长度较小的情况下.
如果是服务器有几亿条数据,类似于微博等体量的数据, 就不能将数据全部加载内存,进行处理了. 我刚开始想到的是, 将数据分片遍历,然后快排到一个磁盘文件, 然后一步一步分解出来, 然后管理排序好的 分片文件. 仍然是比较排序好的文件. 这个思路的 IO 操作起来挺耗时, 并且还要管理分片的文件数据.
最好的解决方式可以采用 布隆过滤器的方式, 高效,且极大节省内存占用. 当然这种方式有一定的误差. 不过在一定的业务场景下,可以忽略不计.
2018年11月28日
二、 @synchronized 是什么, 它是什么锁🔐 ?, 用处与注意事项 ?
@synchronized (<#token#>) {
<#statements#>
}
它是一个 iOS 的语法糖, 用来避免资源竞争导致的数据访问问题.
它的底层是 一个 递归互斥锁
需要注意的是
- 避免标志
token释放, 一般不建议使用self, 而是使用内部私有成员 - 避免代码临界区的逻辑过于复杂, 耗时不能过长
2018年11月29日
三 属性关键词 atomic 的含义 与锁有什么关系 ?
- 作用:
atomic用于保证属性setter、getter的原子性操作
Getter
id objc_getProperty_non_gc(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic) {
// Atomic retain release world
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
id value = objc_retain(*slot);
slotlock.unlock();
// for performance, we (safely) issue the autorelease OUTSIDE of the spinlock.
return objc_autoreleaseReturnValue(value);
}
Setter
static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy)
{
...
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
oldValue = *slot;
*slot = newValue;
slotlock.unlock();
...
objc_release(oldValue);
}
- 源码中
spinlock_t是 Linux 内核自旋锁 spinlock_t 对于自旋锁, 在关联对象中也有使用. 详细可以看 灯塔的 关联对象 AssociatedObject 完全解析
- 它仅仅保证了
accessor的原子性 (对仅仅是方法, 不是成员变量), 不会在读写时发生Crash,但并不能保证 线程的安全性
我第一次看这个源码的时候, 就觉得,根据 slot获取的是同一个 spinlock_t, 以我有限的锁知识,也知道多个线程访问同一个属性的 setter 和 getter 也必须是依次进行的.
然后我看到 如下文章
Realm-property 中的描述如下
Atomic is the default: if you don’t type anything, your property is atomic. An atomic property is guaranteed that if you try to read from it, you will get back a valid value. It does not make any guarantees about what that value might be, but you will get back good data, not just junk memory. What this allows you to do is if you have multiple threads or multiple processes pointing at a single variable, one thread can read and another thread can write. If they hit at the same time, the reader thread is guaranteed to get one of the two values: either before the change or after the change. What atomic does not give you is any sort of guarantee about which of those values you might get. Atomic is really commonly confused with being thread-safe, and that is not correct. You need to guarantee your thread safety other ways. However, atomic will guarantee that if you try to read, you get back some kind of value.
举例子说明就是
例如对于属性 name, 同时有多个线程操作该元素, 也就是调用 setter getter 方法
- 线程 threadReader 读 name
- 线程 threadWriter 写 name
- 那么 threadReader 被保证一定能获取到值, 但是值的内容可能有 ??????
- threadWriter 写之前的值
- threadWriter 写之后的值
但是我对于这个说法是持怀疑态度的, 多个线程调用多核的情况下, 会发生
setter和getter的访问顺序无法确定, 但是如果线程threadReader在对于已经被threadWriter加锁的情况, 仍然是要等待另一个线程threadWriter完成,才可以继续访问的, 也就是说,在一个线程threadReader等待的那一刻,我们会明确知道, 最后获取到的值,一定是threadWriter改写完成后的值, 不存在不确定的现象. 所以我觉得上的说法是不对的
而对于 官方表述ocProperties
Properties are atomic by default so that synthesized accessors provide robust access to properties in a multithreaded environment—that is, the value returned from the getter or set via the setter is always fully retrieved or set regardless of what other threads are executing concurrently.
😅 翻译不出来了, 大体意思就是,多线程环境下,可以保证 `setter` 和 `getter` 被有效的执行.
最后我在 Peak 大神 那里找到了比较靠谱的说法. iOS多线程到底不安全在哪里? 还是要有一定的计算机原理知识啊.
摘录如下: 设置atomic之后,默认生成的getter和setter方法执行是原子的。也就是说,当我们在线程1执行getter方法的时候(创建调用栈,返回地址,出栈),线程B如果想执行setter方法,必须先等getter方法完成才能执行。举个例子,在32位系统里,如果通过getter返回64位的double,地址总线宽度为32位,从内存当中读取double的时候无法通过原子操作完成,如果不通过atomic加锁,有可能会在读取的中途在其他线程发生setter操作,从而出现异常值。如果出现这种异常值,就发生了多线程不安全。
@property (atomic, assign) int intA;
//thread A
for (int i = 0; i < 10000; i ++) {
self.intA = self.intA + 1;
NSLog(@"Thread A: %d\n", self.intA);
}
//thread B
for (int i = 0; i < 10000; i ++) {
self.intA = self.intA + 1;
NSLog(@"Thread B: %d\n", self.intA);
}
摘录: 即使我将intA声明为atomic,最后的结果也不一定会是20000。原因就是因为self.intA = self.intA + 1;不是原子操作,虽然intA的getter和setter是原子操作,但当我们使用intA的时候,整个语句并不是原子的,这行赋值的代码至少包含读取(load),+1(add),赋值(store)三步操作,当前线程store的时候可能其他线程已经执行了若干次store了,导致最后的值小于预期值。这种场景我们也可以称之为多线程不安全.
总之: 原子性能保证代码串行的执行,能保证代码执行到一半的时候,不会有另一个线程介入. 但是要做到真正的多线程安全,还是要在, 多线程的场景下, 检查哪里是 临界区, 同时给 读和写都需要加锁, 并多做测试来解决这一类问题.
常用锁
@synchronized(token)- 递归互斥锁, 对象哈希, 互斥锁数组
NSLock- 封装的
pthread_mutex互斥锁
- 封装的
- 信号量
dispatch_semaphore_t- 底层也是 互斥锁
pthread_mutex- 互斥锁
OSSpinLock唯一一个使用过的自旋锁了, 不过它安全, 不会被使用了- 不再安全的 OSSpinLock
- 有人用
os_unfair_lock替换 os_unfair_lock example - 有人用
dispatch_semaphore_t替换 ,YYModel中的替换方案
多线程问题 摘自 Peak 大佬的 如何用Xcode8解决多线程问题
- 基本类型的
data race① , 例如多线程count ++, 没有Crash, 但数据错乱 - 复杂类型如结构体、类的
data race② 多线程多写操作, 容易 坏内存访问导致Crash data race③ 内存泄露 多线程读一个标志位, 从而多次进入 标志位的代码临界区- 程序的控制流程在多线程的情况下,错乱; 编译器错误优化
memory barrier
多线程问题调试
- 模拟器开启
Thread Sanitizer, 必须是iPhone 5s之后的64位系统 - 长时间运行调试
参考
2018年12月02日
Member discussion